28 KiB
| title | author | date |
|---|---|---|
| recovering a rook-ceph cluster when all hope seems to be lost | 0x3bb | M08-10-2024 |
I share a rook-ceph cluster between a friend of mine approximately 2000km away. I had reservations whether this would be a good idea at first because of the latency and the fact consumer grade WAN might bring anything that breathes to its knees. However, I'm pleased with how robust it has been under those circumstances.
Getting started with rook-ceph is really simple because it orchestrates everything for you. That's convenient, although, if and when you have problems, you can suddenly become an operator of a distributed system that you may know very little about due to the abstraction.
During this incident, I found myself in exactly that position, relying heavily on the (great) documentation for both rook and ceph itself.
the beginning
In the process of moving nodes, I accidentally zapped 2 OSDs.
Given that the "ceph cluster" is basically two bedrooms peered together, we were down to the final OSD.
This sounds bad, but it was fine: mons were still up, just a matter of removing the old OSDs from the tree and letting replication work its magic.
the real mistake
I noticed although the block pool was replicated, we had lost all our RADOS object storage.
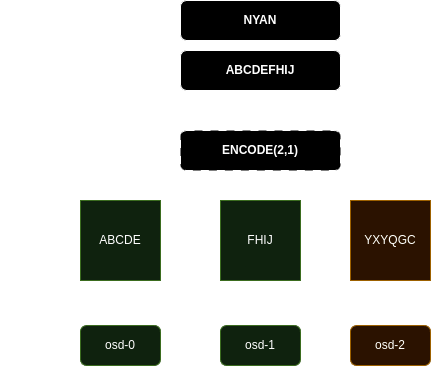
The erasure-coding profile was k=2, m=1. That meant we could only lose 2
OSDs, which had already happened.
Object storage (which our applications interfaced with via Ceph S3 Gateway) was lost. Nothing critical -- we just needed our CSI volume mounts back online for databases -- packages and other artifacts could easily be restored from backups.
Moving on from this, the first thing I did was "fix" the EC configuration to
k=3, m=2. This would spread the data over 5 OSDs.
- dataChunks: 2
- codingChunks: 1
+ dataChunks: 3
+ codingChunks: 2
Happy with that, I restored a backup of the objects. Everything was working.
A few days later, renovatebot arrived with a new PR to bump rook-ceph 1.14.9.
Of course I want that -- the number is bigger than the previous number so everything is going to be better than before.
downtime
Following the merge, all services on the cluster went down at once. I checked
the OSDs which were in CrashLoopBackOff. Inspecting the logs, I saw a bunch
of gibberish and decided to check out the GitHub issues. Since nothing is ever
my fault, I decided to see who or what was to blame.
With no clues, I had still hoped this would be relatively simple to fix.
Resigning to actually reading the OSD logs in the rook-ceph-crashcollector
pods, I saw (but did not understand) the problem:
osd/ECUtil.h: 34: FAILED ceph_assert(stripe_width % stripe_size == 0)
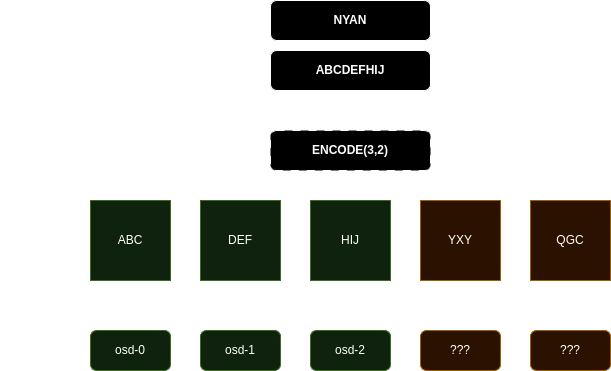
With the "fixed" configuration, what I had actually done is split the object store pool across 5 OSDs. We had 3.
Due to the rook-ceph-operator being rescheduled from the version bump, the
OSD daemons had been reloaded as part of the update procedure and now demanded
an answer for the data and coding chunks that simply did not exist. Sure enough,
ceph -s also reported undersized placement groups.
This makes sense as there weren't enough OSDs to split the data.
from bad to suicide
reverting erasure-coding profile
The first attempt I made was to revert the EC profile back to k=2, m=1. The
OSDs were still in the same state complaining about the erasure-coding
profile.
causing even more damage
The second attempt (and in hindsight, a very poor choice) was to zap the other two underlying OSD disks:
[ osd-1, osd-2 ].
zap.sh
DISK="/dev/vdb"
# Zap the disk to a fresh, usable state (zap-all is important, b/c MBR has to be clean)
sgdisk --zap-all $DISK
# Wipe a large portion of the beginning of the disk to remove more LVM metadata that may be present
dd if=/dev/zero of="$DISK" bs=1M count=100 oflag=direct,dsync
# SSDs may be better cleaned with blkdiscard instead of dd
blkdiscard $DISK
# Inform the OS of partition table changes
partprobe $DISK
Perhaps having two other OSDs online would allow me to replicate the healthy pgs without the offending RADOS objects.
Sure enough, the 2 new OSDs started.
Since the osd-0 with the actual data still wouldn't start, the cluster was
still in a broken state.
Now down to the last OSD, at this point I knew that I was going to make many,
many more mistakes. If I was going to continue I needed to backup the logical
volume used by the osd-0 node before continuing, which I did.
clutching at mons
I switched my focus to a new narrative: something was wrong with the mons.
They were in quorum but I still couldn't figure out why the now last-surviving OSD was having issues starting.
The mon_host configuration was correct in secret/rook-ceph-config:
mon_host: '[v2:10.50.1.10:3300,v1:10.50.1.10:6789],[v2:10.50.1.11:3300,v1:10.50.1.11:6789],[v2:10.55.1.10:3300,v1:10.55.1.10:6789]'
Nothing had changed with the underlying data on those mons. Maybe there was
corruption in the monitor store? The monitors maintain a map of the cluster
state: the osdmap, the crushmap, etc.
My theory was: if the cluster map did not have the correct placement groups and other OSD metadata then perhaps replacing it would help.
I replaced the data from another mon to the one used for the failing OSD
deployment (store.db) and scaled up the deployment:
2024-08-04T00:49:47.698+0000 7f12fc78f700 0 mon.s@2(probing) e30 removed from monmap, suicide.
With all data potentially lost and it being almost 1AM, that message was not very reassuring. I did manually change the monmap and inject it back in, but ended up back in the same position.
I figured I had done enough experimenting at this point and had to look deeper outside of the deployment. The only meaningful change we had made was the erasure-coding profile.
initial analysis
First, I looked back to the OSD logs. They are monstrous, so I focused on the erasure-coding errors:
2024-08-03T18:58:49.845+0000 7f2a7d6da700 1 osd.0 pg_epoch: 8916
pg[12.11s2( v 8915'287 (0'0,8915'287] local-lis/les=8893/8894 n=23 ec=5063/5059
lis/c=8893/8413 les/c/f=8894/8414/0 sis=8916 pruub=9.256847382s)
[1,2,NONE]p1(0) r=-1 lpr=8916 pi=[8413,8916)/1 crt=8915'287 mlcod 0'0 unknown
NOTIFY pruub 20723.630859375s@ mbc={}] state<Start>: transitioning to Stray
2024-08-03T18:58:49.849+0000 7f2a7ced9700 -1G
/home/jenkins-build/build/workspace/ceph-build/ARCH/x86_64/AVAILABLE_ARCH/x86_64/AVAILABLE_DIST/centos8/DIST/centos8/MACHINE_SIZE/gigantic/release/18.2.2/rpm/el8/BUILD/ceph-18.2.2/src/osd/ECUtil.h:
In function 'ECUtil::stripe_info_t::stripe_info_t(uint64_t, uint64_t)' thread
7f2a7e6dc700 time 2024-08-03T18:58:49.853351+0000
/home/jenkins-build/build/workspace/ceph-build/ARCH/x86_64/AVAILABLE_ARCH/x86_64/AVAILABLE_DIST/centos8/DIST/centos8/MACHINE_SIZE/gigantic/release/18.2.2/rpm/el8/BUILD/ceph-18.2.2/src/osd/ECUtil.h:
34: FAILED ceph_assert(stripe_width % stripe_size == 0)
-2> 2024-08-03T18:59:00.086+0000 7ffa48b48640 5 osd.2 pg_epoch: 8894 pg[12.9(unlocked)] enter Initial
...
/src/osd/ECUtil.h: 34: FAILED ceph_assert(stripe_width % stripe_size == 0)
I noticed a pattern: all the failing pg IDs were prefixed with 12.
Seeing this, I had concluded:
- mons were ok and in quorum;
- the
osd-0daemon fails to start; - other fresh OSDs (
osd-1andosd-2) start fine, this was a data integrity issue confined toosd-0(and the previous OSDs had I not nuked them); - the cause was a change in the erasure-coding profile, which happened on only one pool where the chunk distribution was modified;
Accepting the loss of the miniscule data on the object storage pool in favor of saving the block storage, I could correct the misconfiguration.
preparation
To avoid troubleshoting issues caused from my failed attempts, I decided I would do a clear out of the existing CRDs and just focus first on getting the OSD with the data back online. If I ever got the data back, then I'd probably be conscious of prior misconfiguration and have to do so regardless.
- backup the important shit;
- clear out the
rook-cephnamespace;
backups
- the logical volume for
osd-0, so I can re-attach it and afford mistakes; /var/lib/rookon all nodes, containing mon data;
removal
deployments/daemonsets
These were the first to go, as I didn't want the rook-operator persistently
creating Kubernetes objects when I was actively trying to kill them.
crds
Removal of the all rook-ceph resources, and their finalizers to protect them from being removed:
cephblockpoolradosnamespacescephblockpoolscephbucketnotificationscephclientscephclusterscephcosidriverscephfilesystemmirrorscephfilesystemscephfilesystemsubvolumegroupscephnfsescephobjectrealmscephobjectstorescephobjectstoreuserscephobjectzonegroupscephobjectzonescephrbdmirrors
/var/lib/rook
I had these backed up for later, but I didn't want them there when the cluster came online.
osd disks
I did not wipe any devices.
First, I obviously didn't want to wipe the disk with the data on it. As for the
other, now useless OSDs that I had mistakenly created over the old ones; I knew
spawning the rook-operator would create new OSDs if they didn't belong to an
old ceph cluster.
This would make troubleshooting osd-0 more difficult, as I'd now have to consider
analysing the status reported from osd-1 and osd-2.
provisioning
Since at this point I only cared about osd-0 and it was beneficial to have
fewer moving parts to work with, I changed the rook-ceph-cluster mon count to 1
within the helm values.yaml.
Following this, I simply reconciled the chart.
I noticed the rook-ceph-operator, rook-ceph-mon-a, rook-ceph-mgr-a came online as expected.
Because the OSDs were part of an old cluster, I now had a ceph-cluster with no
OSDs, as shown in the rook-ceph-osd-prepare-* jobs for each node.
osd.0: "cd427c63-b43f-40cb-99a4-7f58af25d624" belonging to a different ceph cluster "47f25963-57c0-4b3b-9b35-bbf68c09eec6"
osd.1: "cd427c63-b43f-40cb-99a4-7f58af25d624" belonging to a different ceph cluster "47f25963-57c0-4b3b-9b35-bbf68c09eec6"
osd.2: "cd427c63-b43f-40cb-99a4-7f58af25d624" belonging to a different ceph cluster "47f25963-57c0-4b3b-9b35-bbf68c09eec6"
surgery
With less noise and a clean slate, it was time to attempt to fix this mess.
- adopt
osd-0to the new cluster; - remove the corrupted pgs from
osd-0; - bring up two new OSDs for replication;
osd-0
I started trying to determine how I would safely remove the offending objects. If that happened, then the OSD would have no issues with the erasure-coding profile since the pgs wouldn't exist, and the OSD daemon should start.
-
If the placement groups contained only objects created from the RADOS Object Gateway, then I can simply remove the pgs.
-
If, however, the pgs contain both the former and block device objects then it would require careful removal of all non-rdb (block storage) objects as there would be valuable data loss by purging the entire placement groups.
Since OSD pools have a 1:N relationship with pgs, the second scenario seemed
unlikely, perhaps impossible.
Next, I needed to inspect the OSD somehow, because the existing deployment would continously crash.
kubectl rook-ceph debug start rook-ceph-osd-0
Running this command allowed me to observe the OSD without it actually joining the cluster. The "real" OSD deployment need only be scheduled, but crashing continously was ok.
Once you execute that command, it will scale the OSD daemon down and create a new deployment that mirrors the configuration but without the daemon running in order to perform maintenance.
Now in a shell of the debug OSD container, I confirmed these belonged to the object storage pool.
[root@rook-ceph-osd-0-maintenance-686bbf69cc-5bcmj ceph]# ceph pg ls-by-pool ceph-objectstore.rgw.buckets.data
PG OBJECTS DEGRADED MISPLACED UNFOUND BYTES OMAP_BYTES* OMAP_KEYS* LOG LOG_DUPS STATE SINCE VERS
12.0 0 0 0 0 0 0 0 0 unknown 8h
12.1 0 0 0 0 0 0 0 0 unknown 8h
12.2 0 0 0 0 0 0 0 0 unknown 8h
12.3 0 0 0 0 0 0 0 0 unknown 8h
12.4 0 0 0 0 0 0 0 0 unknown 8h
12.5 0 0 0 0 0 0 0 0 unknown 8h
12.6 0 0 0 0 0 0 0 0 unknown 8h
12.7 0 0 0 0 0 0 0 0 unknown 8h
12.8 0 0 0 0 0 0 0 0 unknown 8h
12.9 0 0 0 0 0 0 0 0 unknown 8h
12.a 0 0 0 0 0 0 0 0 unknown 8h
12.b 0 0 0 0 0 0 0 0 unknown 8h
12.c 0 0 0 0 0 0 0 0 unknown 8h
12.d 0 0 0 0 0 0 0 0 unknown 8h
12.e 0 0 0 0 0 0 0 0 unknown 8h
12.f 0 0 0 0 0 0 0 0 unknown 8h
12.10 0 0 0 0 0 0 0 0 unknown 8h
12.11 0 0 0 0 0 0 0 0 unknown 8h
12.12 0 0 0 0 0 0 0 0 unknown 8h
12.13 0 0 0 0 0 0 0 0 unknown 8h
12.14 0 0 0 0 0 0 0 0 unknown 8h
12.15 0 0 0 0 0 0 0 0 unknown 8h
12.16 0 0 0 0 0 0 0 0 unknown 8h
12.17 0 0 0 0 0 0 0 0 unknown 8h
12.18 0 0 0 0 0 0 0 0 unknown 8h
12.19 0 0 0 0 0 0 0 0 unknown 8h
12.1a 0 0 0 0 0 0 0 0 unknown 8h
12.1b 0 0 0 0 0 0 0 0 unknown 8h
Seeing this, I first checked to see how many placement groups prefixed with 12 existed using the actual path to the OSD.
[root@rook-ceph-osd-0-maintenance-686bbf69cc-5bcmj ceph]# ceph-objectstore-tool --data-path /var/lib/ceph/osd/ceph-0 --op list-pgs | grep ^12
12.bs1
12.6s1
12.1fs0
12.1ds1
12.15s0
12.16s0
12.11s0
12.12s2
12.0s0
12.17s2
12.4s1
12.9s0
12.19s0
12.cs2
12.13s0
12.14s2
12.3s2
12.1as0
12.1bs2
12.as1
12.1es1
12.1cs2
12.2s2
12.8s1
12.7s2
12.ds0
12.es0
12.fs0
12.18s0
12.1s0
12.5s1
12.10s2
I still needed to be convinced I wasn't removing any valuable data. I inspected a few of them to be sure.
[root@rook-ceph-osd-0-maintenance-686bbf69cc-5bcmj ceph]# ceph-objectstore-tool --data-path /var/lib/ceph/osd/ceph-0 --pgid 12.10s0 --op list
"12.10s0", {"oid" :"7d92708-bd9b-4d4b-bfc1-d331eb216e68.21763481.3__shadow_packages/07/19/071984080b32e2867 f 1ac6ec2b7d2b8724bc5d75e2850b5e7 f20040ee52F55d1.2~e7rYg3S
"hash" :1340195137, "max":0, "pool":12, "namespace":"","shard_id":2, "max":0}
"12.10s0", {"oid" :"7d92708-bd9b-4d4b-bfc1-d331eb216e68.21763481.3__shadow_packages/9a/82/9a82a64c3a8439c75d8e584181427b073712afd1454747bec3dcb84bcbe19ac5. 2~urbG4nd
"hash" :4175566657, "max":0, "pool":12, "namespace":"","shard_id":2, "max":0}
"12.10s0", {"oid" :"7d927F08-bd9b-4d4b-bfc1-d331eb216e68.22197937.1__shadow Windows Security Internals.pdf.2~g9stQ9inkWvsTq33S9z5xNEHEgST2H4.1_1","key":"", "snapid":-
"shard id":2,"max":0}]
...
With this information, I now knew:
- the log exceptions matched the pgs that were impacted from the change in the erasure-coding configuration;
ceph-objectstore.rgw.buckets.datahad a relationship with those pgs where the configuration was changed;- the objects were familiar with the objects in the buckets, e.g. books;
Since I did modify the erasure-coding profile this is all starting to make sense.
Carefully, the next operation was to remove the offending placement groups. Simply removing the pool wouldn't work, as the OSD daemon not starting meant it would know nothing about this change, and still not have enough chunks to come alive.
[root@rook-ceph-osd-0-maintenance-686bbf69cc-5bcmj ceph]# ceph-objectstore-tool --data-path /var/lib/ceph/osd/ceph-0 --op remove --type bluestore --force --pgid 12.17s2
marking collection for removal
setting '_remove' omap key
finish_remove_pgs 12.17s2_head removing 12.17s2
Remove successful
[root@rook-ceph-osd-0-maintenance-686bbf69cc-5bcmj ceph]# ceph-objectstore-tool --data-path /var/lib/ceph/osd/ceph-0 --op remove --type bluestore --force --pgid 12.0s0
marking collection for removal
setting '_remove' omap key
finish_remove_pgs 12.0s0_head removing 12.0s0
Remove successful
I did this for every PG listed above. Once I scaled down the maintenance
deployment, I then scaled back deployment/rook-ceph-osd-0 to start the daemon
with (hopefully) agreeable placement groups and thankfully, it had come alive.
k get pods -n rook-ceph
rook-ceph-osd-0-6f57466c78-bj96p 2/2 Running
An eager run of ceph -s produced both relief and disappointment. The OSD was up, but the pgs were in an unknown state.
ceph -s
...
data:
pools: 12 pools, 169 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs: 100.000% pgs unknown
169 unknown
At this point, I had mentioned to my friend (helping by playing GuildWars 2)
that we might be saved. It seemed promising as we at least had osd-0 running
again now that the troublesome pgs were removed.
He agreed, and contemplated changing his character's hair colour instead of saving our data.
mons
restoring
I had /var/lib/rook backups from each node with the old mon data. At this
point, with the correct number of placement groups and seeing 100% of them
remaining in an unknown state, it seemed the next step was to restore the
mons.
I knew from reading the rook-ceph docs that if you want to restore the data
of a monitor to a new cluster, you have to inject the monmap into the old
mons store.db.
Before doing this, I scaled deployment/rook-ceph-mon-a down to 0 first.
Then, navigating to a directory on my local machine with the backups I ran a
container to modify the monmap on my local fs.
docker run -it --rm --entrypoint bash -v .:/var/lib/rook rook/ceph:v1.14.9
touch /etc/ceph/ceph.conf
cd /var/lib/rook
ceph-mon --extract-monmap monmap --mon-data ./mon-q/data
monmaptool --rm q
monmaptool --rm s
monmaptool --rm t
Now the old mons q, s and t were removed from the map, I had to add the
new cluster mon rook-ceph-mon-a created following the new
ceph-cluster.
monmaptool --addv a '[v2:10.50.1.10:3300,v1:10.50.1.10:6789]`
ceph-mon --inject-monmap monmap --mon-data ./mon-q/data
exit
Shoving it back up to the node rook-ceph-mon-a lives on:
scp -r ./mon-q/data/* 3bb@10.50.1.10:/var/lib/rook/mon-a/data/
Rescheduling the deployment and although the mon log output isn't giving me
suggestions of suicide, all our pgs still remain in an unknown state.
recovering the mon store
It turns out that you can actually recover the mon store. It's not a huge deal so long as your OSDs have data integrity.
Scaling the useless mon-a down, I copied the existing mon-a data onto the
rook-ceph-osd-0 daemon container.
Another osd-0 debug container... k rook-ceph debug start rook-ceph-osd-0
I rebuilt the mon data, using the existing RocksDB kv store.
This would have worked without the backup, but I was interested to see the
osdmaps trimmed due to the other 2 removed OSDs.
[root@he-prod-k3s-controlplane-ch-a-1 ceph]# ceph-objectstore-tool --type bluestore --data-path /var/lib/ceph/osd/ceph-0/ --op update-mon-db --mon-store-path /tmp/mon-a/data/ osd.0 : 3099 osdmaps trimmed, 635 osdmaps added.
[root@he-prod-k3s-controlplane-ch-a-1 ceph]# ceph-authtool /tmp/mon-a/keyring -n mon. --cap mon 'allow *' --gen-key
[root@he-prod-k3s-controlplane-ch-a-1 ceph]# ceph-monstore-tool /tmp/mon-a/data rebuild -- --keyring /tmp/mon-a/keyring 4 rocksdb: [db/flush_job.cc:967] [default] [JOB 3] Level-0 flush table #3433: 62997231 bytes OK 4 rocksdb: EVENT_LOG_v1 {"time_micros": 1722831731454649, "job": 3, "event": "flush_finished", "output_compression": "NoCompression", "lsm_state": [2, 0, 0, 0, 0, 0, 2], "immutable_memtables": 1} 4 rocksdb: [file/delete_scheduler.cc:74] Deleted file /tmp/mon-a/data/store.db/003433.sst immediately, rate_bytes_per_sec 0, total_trash_size 0 max_trash_db_ratio 0.250000 4 rocksdb: EVENT_LOG_v1 {"time_micros": 1723067397472153, "job": 4, "event": "table_file_deletion", "file_number": 3433} 4 rocksdb: [db/db_impl/db_impl.cc:704] Shutdown complete
After copying the now _rebuilt_ `mon-a` store back, and bringing everything up
again, the cluster was finally resurrecting.
It took some time for the rebalancing and replication to occur, but hours
later, `ceph -s` reported a healthy cluster and services resumed being entirely
unaware of the chaos that had ensued over the previous few days:
cluster: id: 47f25963-57c0-4b3b-9b35-bbf68c09eec6 health: HEALTH_OK
services: mon: 3 daemons, quorum a,b,c (age 3h) mgr: b(active, since 8h), standbys: a mds: 1/1 daemons up, 1 hot standby osd: 3 osds: 3 up (since 3h), 3 in (since 3h) rgw: 2 daemons active (2 hosts, 1 zones)
data: volumes: 1/1 healthy pools: 12 pools, 169 pgs objects: 4.88k objects, 16 GiB usage: 47 GiB used, 1.1 TiB / 1.2 TiB avail pgs: 169 active+clean
io: client: 639 B/s rd, 9.0 KiB/s wr, 1 op/s rd, 1 op/s wr recovery: 834 KiB/s, 6 objects/s
It seemed like a miracle, but it is entirely credited to how resilient ceph is
built to tolerate that level of abuse.
# why
_Data appears to be lost_
- ceph OSD daemons fail to start;
- the OSDs could not reconstruct the data from chunks;
- the `osdmap` referenced a faulty erasure-coding profile;
- the monstore `osdmap` still had reference to the above erasure-coding profile;
- the erasure-coding profile was changed to a topology impossible to satisfy under the current architecture;
- 2 disks were zapped, hitting the ceiling of the failure domain for `ceph-objectstore.rgw.buckets.data_ecprofile`;
The monitor `osdmap` still contained the bad EC profile.
`ceph-monstore-tool /tmp/mon-bak get osdmap > osdmap.bad`
osdmaptool --dump json osdmap.bad | grep -i profile
"erasure_code_profiles":{ "ceph-objectstore.rgw.buckets.data_ecprofile":{ "crush-device-class":"", "crush-failure-domain":"host", "crush-root":"default", "jerasure-per-chunk-alignment":"false", "k":"3", "m":"2" } }
After rebuilding the monstore...
`ceph-monstore-tool /tmp/mon-a get osdmap > osdmap.good`
"erasure_code_profiles":{ "ceph-objectstore.rgw.buckets.data_ecprofile":{ "crush-device-class":"", "crush-failure-domain":"host", "crush-root":"default", "jerasure-per-chunk-alignment":"false", "k":"3", "m":"1" } }
Therefore, it seems as if I could have attempted to rebuild the monstore first,
possibly circumventing the `ECAssert` errors. The placement groups on `osd-0` were
still mapping to 3 OSDs, not 5.
[root@ad9e4c6e7343 rook]# osdmaptool --test-map-pgs-dump --pool 12 osdmap osdmaptool: osdmap file 'osdmap' pool 12 pg_num 32 12.0 [2147483647,2147483647,2147483647] -1 12.1 [2147483647,2147483647,2147483647] -1 12.2 [2147483647,2147483647,2147483647] -1 12.3 [2147483647,2147483647,2147483647] -1 12.4 [2147483647,2147483647,2147483647] -1 12.5 [2147483647,2147483647,2147483647] -1 12.6 [2147483647,2147483647,2147483647] -1 12.7 [2147483647,2147483647,2147483647] -1 12.8 [2147483647,2147483647,2147483647] -1 12.9 [2147483647,2147483647,2147483647] -1 12.a [2147483647,2147483647,2147483647] -1 12.b [2147483647,2147483647,2147483647] -1 12.c [2147483647,2147483647,2147483647] -1 12.d [2147483647,2147483647,2147483647] -1 12.e [2147483647,2147483647,2147483647] -1 12.f [2147483647,2147483647,2147483647] -1 12.10 [2147483647,2147483647,2147483647] -1 12.11 [2147483647,2147483647,2147483647] -1 12.12 [2147483647,2147483647,2147483647] -1 12.13 [2147483647,2147483647,2147483647] -1 12.14 [2147483647,2147483647,2147483647] -1 12.15 [2147483647,2147483647,2147483647] -1 12.16 [2147483647,2147483647,2147483647] -1 12.17 [2147483647,2147483647,2147483647] -1 12.18 [2147483647,2147483647,2147483647] -1 12.19 [2147483647,2147483647,2147483647] -1 12.1a [2147483647,2147483647,2147483647] -1 12.1b [2147483647,2147483647,2147483647] -1 12.1c [2147483647,2147483647,2147483647] -1 12.1d [2147483647,2147483647,2147483647] -1 12.1e [2147483647,2147483647,2147483647] -1 12.1f [2147483647,2147483647,2147483647] -1 #osd count first primary c wt wt osd.0 0 0 0 0.488297 1 osd.1 0 0 0 0.488297 1 osd.2 0 0 0 0.195297 1 in 3 avg 0 stddev 0 (-nanx) (expected 0 -nanx)) size 3 32
Since the cluster did not have enough OSDs (wanted 5 with `k=3,m=2`), the rule
can be tested against the old crush map, with `--num-rep` representing the
required OSDs, i.e. `k+m`:
With the original erasure-coding profile (`k+m=3`), everything looks good -- no
bad mappings.
[root@ad9e4c6e7343 rook]# crushtool -i crush --test --num-rep 3 --show-bad-mappings
// healthy
With `k+m=5`, though -- or anything great than `3` OSDs...
[root@ad9e4c6e7343 rook]# crushtool -i crush --test --num-rep 5 --show-bad-mappings ... bad mapping rule 20 x 1002 num_rep 5 result [0,2147483647,1,2,2147483647] bad mapping rule 20 x 1003 num_rep 5 result [0,2147483647,2,1,2147483647] bad mapping rule 20 x 1004 num_rep 5 result [1,0,2147483647,2,2147483647] bad mapping rule 20 x 1005 num_rep 5 result [0,1,2147483647,2,2147483647] bad mapping rule 20 x 1006 num_rep 5 result [0,1,2147483647,2,2147483647] bad mapping rule 20 x 1007 num_rep 5 result [0,1,2147483647,2147483647,2] bad mapping rule 20 x 1008 num_rep 5 result [1,2,0,2147483647,2147483647] bad mapping rule 20 x 1009 num_rep 5 result [2,1,0,2147483647,2147483647] bad mapping rule 20 x 1010 num_rep 5 result [0,1,2,2147483647,2147483647] bad mapping rule 20 x 1011 num_rep 5 result [0,2147483647,2,1,2147483647] bad mapping rule 20 x 1012 num_rep 5 result [0,1,2147483647,2,2147483647] bad mapping rule 20 x 1013 num_rep 5 result [0,2,2147483647,1,2147483647] bad mapping rule 20 x 1014 num_rep 5 result [1,0,2147483647,2,2147483647] bad mapping rule 20 x 1015 num_rep 5 result [2,0,2147483647,1,2147483647] bad mapping rule 20 x 1016 num_rep 5 result [1,0,2,2147483647,2147483647] bad mapping rule 20 x 1017 num_rep 5 result [2,0,1,2147483647,2147483647] bad mapping rule 20 x 1018 num_rep 5 result [1,0,2147483647,2147483647,2] bad mapping rule 20 x 1019 num_rep 5 result [0,1,2,2147483647,2147483647] bad mapping rule 20 x 1020 num_rep 5 result [0,2147483647,1,2147483647,2] bad mapping rule 20 x 1021 num_rep 5 result [2,1,0,2147483647,2147483647] bad mapping rule 20 x 1022 num_rep 5 result [1,0,2,2147483647,2147483647] bad mapping rule 20 x 1023 num_rep 5 result [0,2,1,2147483647,2147483647]
Mappings were found on _3_ OSDs, but missing the 4th and 5th reference as
indicated by the largest 32-bit int (i.e. missing). The object storage data
would still have been lost, but it could have made the recovery of the cluster
significantly less painful.